
Émerson Silva
Software Engineer @oivitalk
Introdução ao Aprendizado de Máquina [PT-BR]
Published Feb 18, 2019
Introdução
Os fenômenos do mundo real, em sua maioria, podem ser descritos como uma função matemática. Quanto mais complexo o evento, mais complexo são as leis que o descreve. Sabendo disso, técnicas de Aprendizado de Máquina exploram dessa característica, usando registros (dados) históricos do fenômeno em questão, para fazer uma aproximação de tais leis (funções), esse processo de aproximação é o que chamamos de aprendizado. No gif abaixo é mostrado esse processo (linha vermelha).
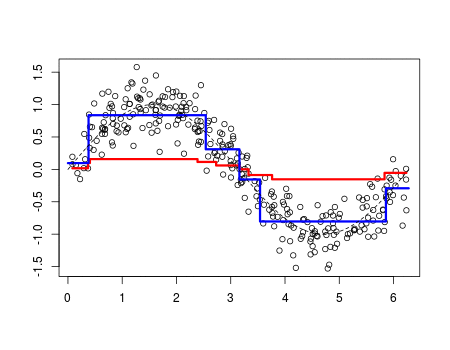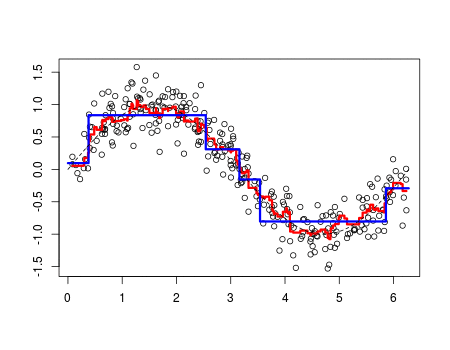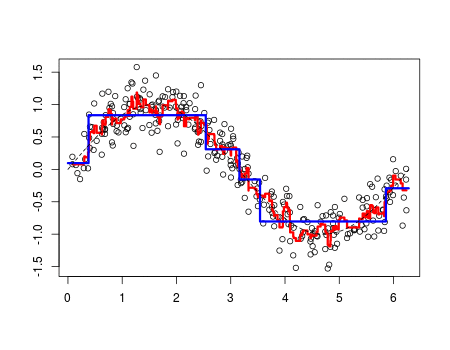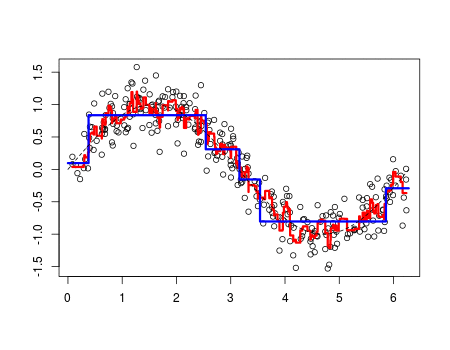
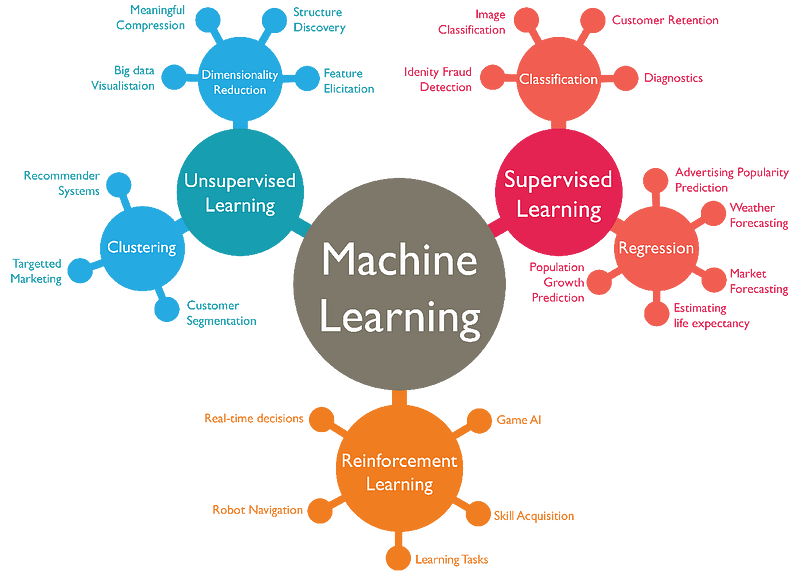
Consequentemente, dependendo da complexidade do fenômeno, uma maior quantidade de dados fornecem uma melhor aproximação. E esse processo de aprendizado pode ocorrer de várias formas, mas dentre as mais usadas estão a supervisionada, não-supervisionada e por reforço. Descreverei brevemente cada uma dessas técnicas abaixo.
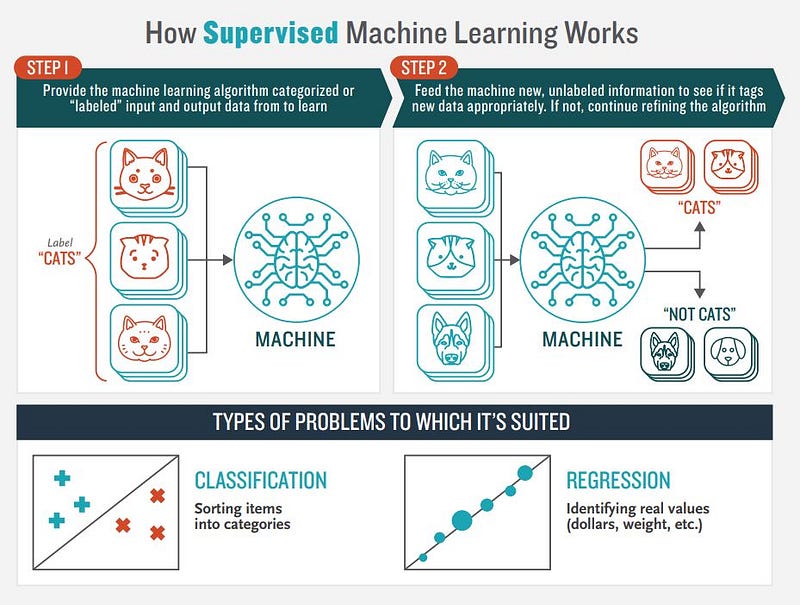
Aprendizado Supervisionado
Usado em cenários que possuem um conjunto de dados com as características de predição e uma característica alvo correspondente de cada instância (ocorrência). O termo supervisionado surge por causa desse suposto “supervisor”, que estará mostrando pro algoritmo qual deve ser o resultado final (característica alvo) para cada combinação de características preditivas no dataset.
O tipo da característica alvo divide o escopo de problemas em dois ramos:
- Problemas de classificação, quando tal característica é discreta (categorias ou classes), ex.: spam ou não spam, gato ou cachorro, etc.
- Problemas regressão quando é contínua (numérica), ex.: cotação do bitcoin, temperatura do planeta ou o número de infectados por alguma endemia.
Aprendizado não-supervisionado
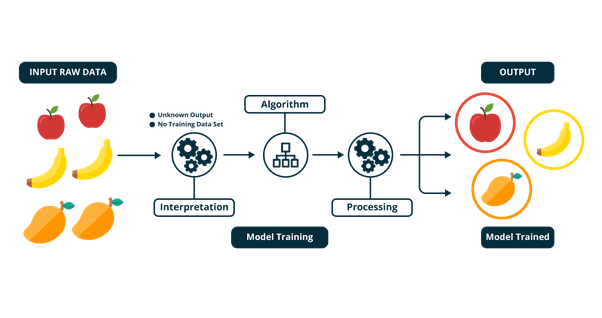
Nesse contexto ocorre o contrário do supervisionado, ou seja, não temos uma descrição de classes ou categorias e queremos criar agrupamentos (clusters) em que os elementos pertencentes possuam características em comum. Esses agrupamentos tornam o entendimento do dataset mais fácil, o que é uma tarefa importante no contexto de um grande volume de dados (Big Data). Além do mais essa técnica é muito usado em problemas de detecção de anomalias.
Aprendizado por reforço
Usado para treinar “agentes” (algoritmos) em determinado ambiente, onde a otimização das ações desse “agente” é guiado pelo acúmulo de recompensas por suas ações até chegar no estado desejado. Ele é muito usado para tarefas da vida real, como: carros autônomos, bots para jogos eletrônicos, robôs, etc. O caso de uso mais famoso desse método é o AlphaGo, IA da DeepMind que derrotou o melhor jogador de Go do mundo.

A imagem abaixo mostra uma visão geral do que foi tratado:
Um fato interessante sobre a maioria dos algoritmos das técnicas citadas é que eles não são relativamente recentes, como o naive Bayes que vem sendo usado desde a década de 1960.
Finalizando…
Depois dessa visão geral e superficial a respeito do Aprendizado de Máquina e suas abordagens, fica mais fácil de perceber as diversas áreas em que esses conceitos e técnicas podem ser aplicados. Diante de toda a evolução de hardware, o aumento da quantidade de dados criada diariamente e a necessidade de entendê-los foram os principais fatores que trouxeram Machine Learning à tona.
“Do or Do not. There is no try” — Yoda